
Site Reliability Engineering (SRE) is an integrated process or practice in Agile development that strives to ensure that operational integrity is maintained by the DevSecOps development process in a scalable way.
SRE is primarily focused on ensuring that Business SLA’s are sustainable and exploit Service Level Objective (SLO) achievement as a meter of targeting effort and defining success. When working well SRE empowers Dev teams to deliver the speed/quality/cost requirements effectively and efficiently through the DevSecOps process.
But what does a good SRE practice look like?
SRE Practice is not fully mature
Adoption of SRE in organisations is at best patchy. A Dynatrace study in 2022 assessed that over 80% or organisations classed as not fully mature. The opportunities area to promote better investment are rich.
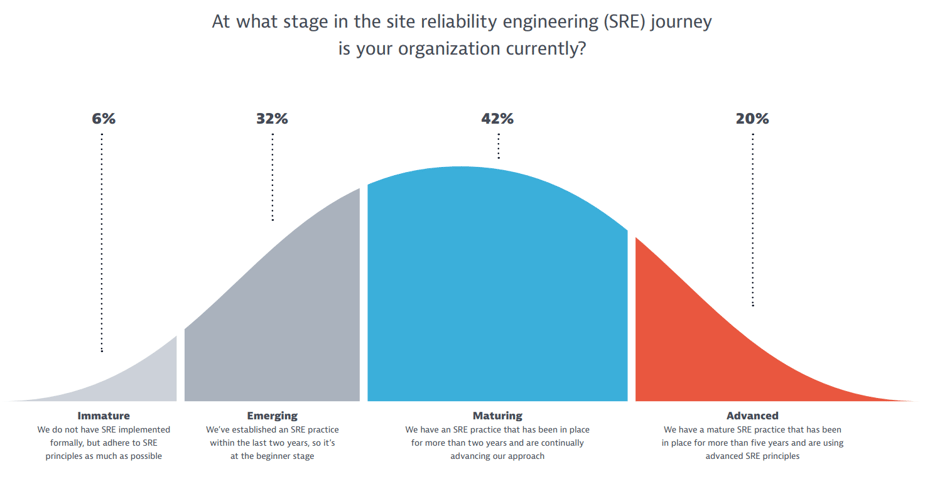
Source: Dynatrace State of SRE Report 2022
Working with the SRE teams of our clients we identified a few common behaviours from not fully mature teams:
-
Performance, Reliability, Recoverability and Capacity get no focus. These are key areas of SLA/SLO that need to be taken into consideration.
-
Integration with cloud services and observability are limited. Core data metrics are not captured nor visible therefore, making operational risk difficult to identify and act upon. Examples of this include cloud metrics for Azure and AWS services which have a high dependency.
-
Cloud costs are uncontrolled and increasing rapidly.
-
No automation frameworks are in place to assist Dev teams with the increasing pace of change objectives. Releases frequently overrun impacting time to market.
In our experience, these behaviours can be turned around in a manner of months into a good internal SRE practice that the business will benefit from.
Signs of a good SRE practice
-
SRE engineers collaborate with developers to deliver stable, resilient, performant, and secure architectures that meet non-requirements set out in SLO’s and SLA’s. Development teams invariably prioritise business change and often spend insufficient time planning for these failure scenarios. SRE bridges this gap from an architectural and testing perspective and exploits lessons learnt from production incidents to fix problems.
-
SRE improves time-to-market by eliminating manual tasks. Examples of this include development, deployment, testing and monitoring frameworks. This ensures that consistent practices are delivered repeatedly through common toolsets & automation thus avoiding duplication of error-prone human intervention.
-
SRE believe that observability is key and provides the capability to visualise operational and SLA performance. Decisions taken are justified by data and use the analysis of this to drive out how the transformation should be implemented. Examples of this include DORA metrics, Incident data, SLO/SLI metrics (Resource and Performance). Immature development teams who tend not to conduct this analysis are encouraged to adopt improved observability practices across all environments.
-
SRE often provide testing specialisms & skills that development teams cannot easily acquire. Examples include Performance, Resilience & recoverability, and penetration testing.
-
Investment in SRE reduces the organisational silos that have historically arisen between development and Ops teams. The shared responsibility and highly collaborative approach between SRE & development supports a more effective and agile approach to the delivery of change.

Also worth having a look at some of our recent case studies where we have saved our clients Millions of pounds in cloud spend.


