
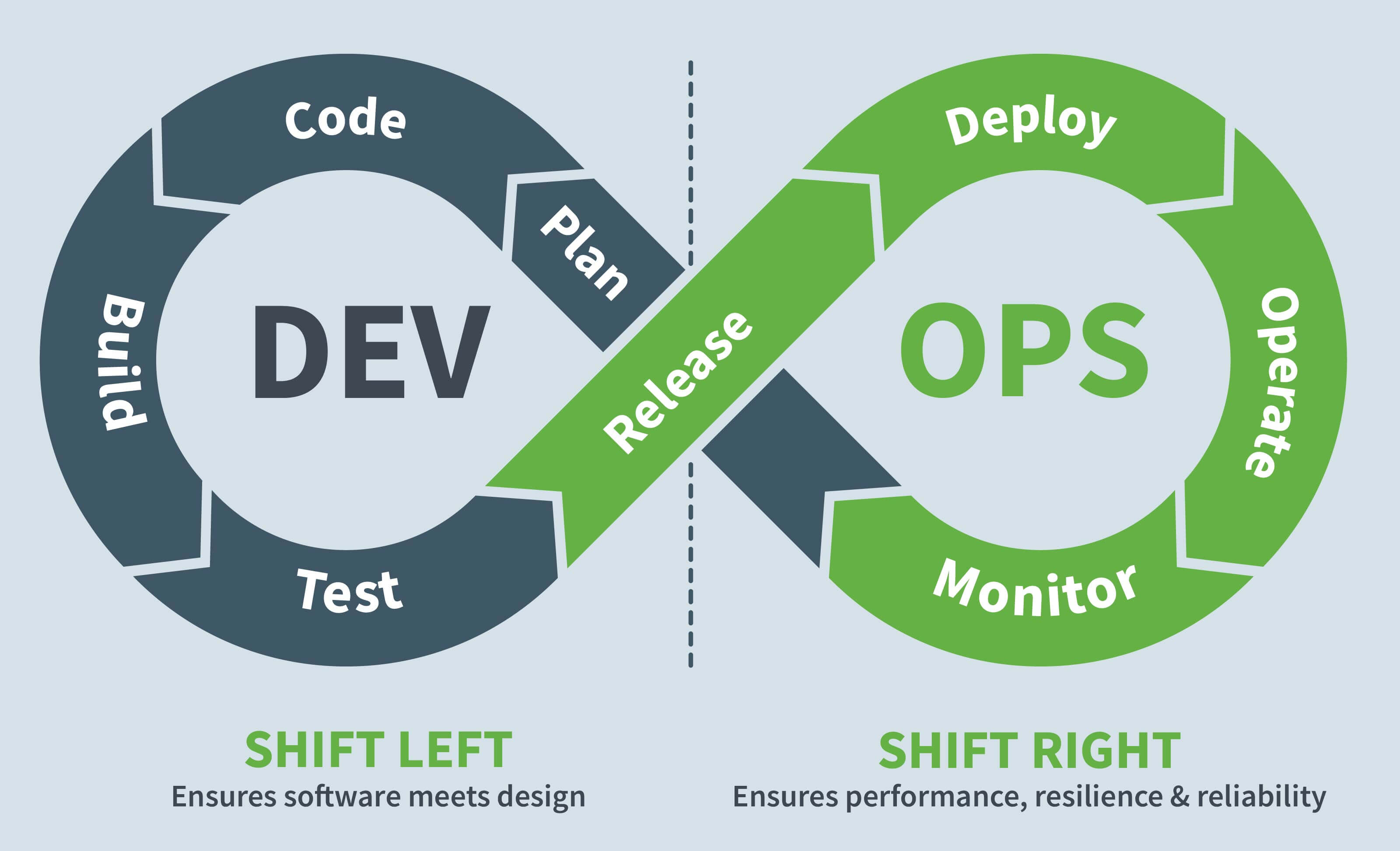
Shifting left or shifting right are DevOps terms that gained immense attention for most Cloud and IT teams. They are the core concepts of the agile DevOps methodology.
Shift left aims to execute quick, automated, repetitive tests to identify bugs and possible risks at critical phases of software development as well as assess risks at the design stage.
The shift right approach monitors behaviour, usage, performance, and security metrics to verify software operability in the hands of its actual users.
At Capacitas, we have deep knowledge and experience of DevOps operating methodology where our expertise has allowed us to help clients with dynamic environments to ensure performance, reduce costs, and scale their critical systems. We know first-hand the challenges and use cases for both “shift left or right” methodologies to implement them effectively.
How Capacitas addresses the problem of not shifting
During a recent engagement a client described themselves as:
- Not being resilient
- Not 24x7
- “Not really” doing any non-functional testing
- Having a high rate of change but also a high rate of priority one incidents
We knew we could improve all the above with several approaches, but the options fell into two categories – Shifting left or shifting right – it is never not shifting!
The first step we need to answer is, “what problem are we trying to solve?”. We do this by undertaking a specific type of risk assessment called a Performance Audit. The objective is to answer the following:
- What are your performance risks?
- What do we recommend to mitigate them?
The risks are categorised in these dimensions so that we can identify where the client should focus their efforts:
- By application/system
- By business area
- By risk level (combination of likelihood and criticality)
- By risk type – this category focuses on Capacitas’ Seven Pillars of Software Performance
- Throughput and Response Time
- Capacity
- Efficiency
- Scalability
- Stability
- Resilience
- Instrumentation
We also identify when skills and processes are the sources of risk.
The mitigations that we recommend will provide confidence to the client that their systems are scalable and capable of meeting demand at an optimised cost. These mitigations can then be categorised as either shifting left or right.
Shifting left
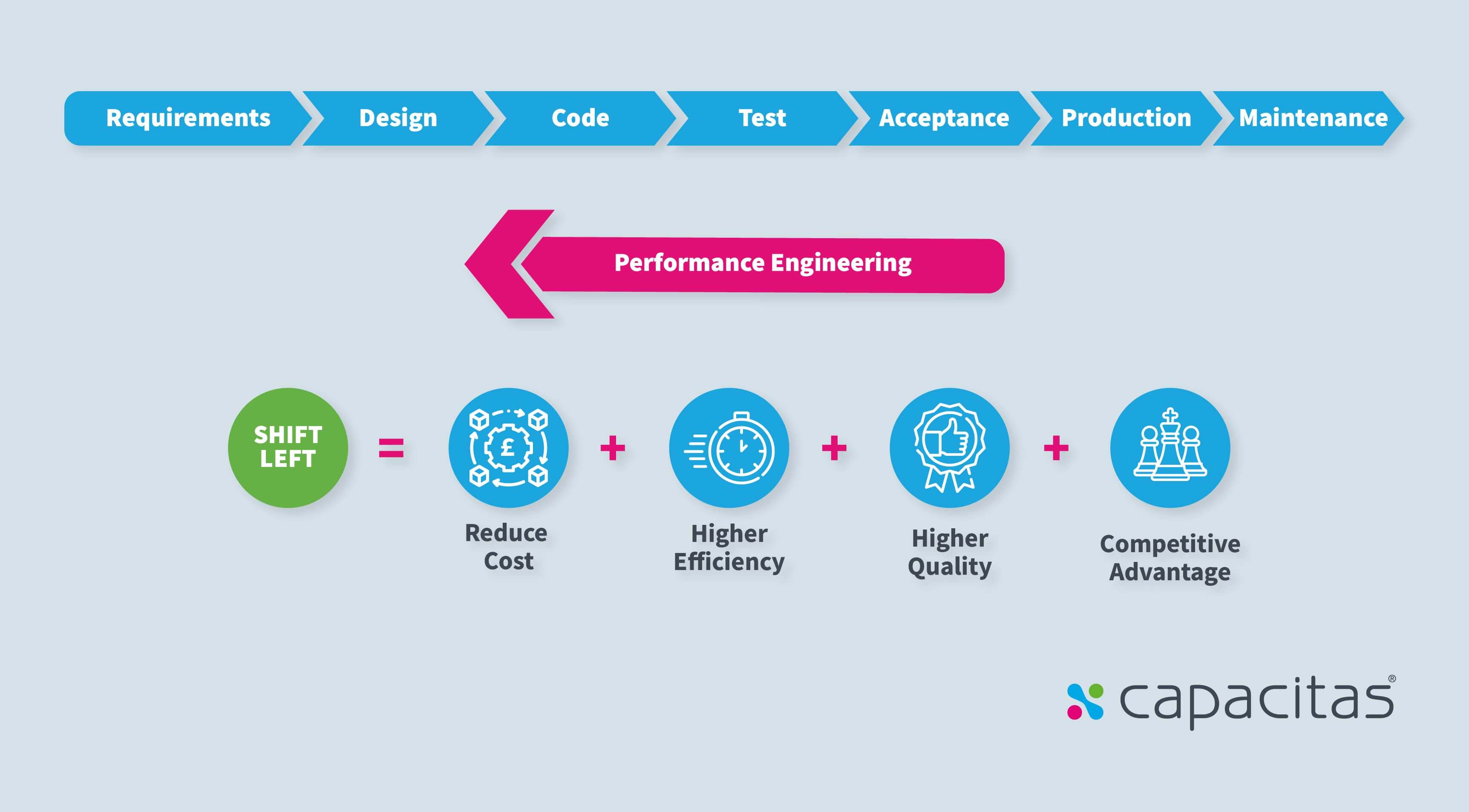
This means intervening before a release goes live. It is thought that the earlier an intervention is made, the more effective and efficient it is (e.g. less expensive). Even if a lot of activity is identified pre-live (e.g. pre-live performance testing), there is scope to shift further left by following performance engineering recommendations to review designs and solutions before they are committed.
There is an often quoted study by the IBM System Science Institute that has found it is 100 times more costly to fix a defect live compared to at the design stage. More importantly, it is:
- 15 times less costly to fix a defect in the Testing stage
- 5 times less costly at the Implementation stage
Fixing a defect in design may be hard to spot. However, it is much less challenging to fix by changing the design before it is approved - compared to fixing it after testing or when it is live. In this case the client had, not been able to spot most issues in testing, as there was no appetite to invest in a representative pre-production environment.
In a previous engagement with the same client, we identified an opportunity of £1m-£2m in cost avoidance by challenging the final infrastructure design, even though this was beyond the final test phase. We could have potentially saved significantly more if there had been an opportunity to influence the performance testing that had been carried out. This is because the testing did not address scalability, it did not measure the resource cost per transaction, and was not done against a representative environment.
The ease of migrating to a cloud solution for testing now, allows more representative testing environments that are
- Scalable i.e. can be small and therefore inexpensive for some requirements but can grow to meet other requirements and
- Flexible, i.e., do not need to be “on” all the time.
Shifting right
Shifting right refers to carrying out assurance activities once a release has gone live. Although resolving the fixes at this stage is expensive, it is still possible to identify defects before they become incidents.
It’s all about learning lessons from production that we cannot learn from testing, for example:
- We don’t know how user behaviour will change when our code goes live.
- Scalability of batch workloads
- It's impossible to test all browser-platform-device combinations
- Testing workloads and models are often inaccurate
An example of this is the popularity of applications like Hugo and Loop since the UK’s energy prices have increased dramatically. These applications allow consumers to analyse their energy usage by requesting for frequent meter readings causing increases the demand on energy providers systems and the critical national infrastructure that supports the messaging between consumers and providers.
The solution was to shift right to deal with such applications using a capacity and performance model that understands the relationship between
- Demand (from users) and resource consumption (physical and logical)
- Resource consumption and response time - These can quantify the effect on systems and support solutions to mitigate the risks that are threatened.
What we have witnessed with several clients is that by simply carrying out what we call “production validation” they can:
- Confirm whether the release is behaving as predicted based on activities earlier in the lifecycle.
- Discover if it relies on a pre-release intervention level
However, a more shift-right approach that we have used successfully is using proactive analytics. This is where existing monitoring data is analysed to identify potential issues such as looping processes, slow steady growth in resource utilisation, missed reboots etc.
One of our clients had large workloads causing them to have small windows to work with the development teams to enable thorough testing. To solve this situation, we helped them shift-right by employing a forensic analysis to their two most critical tiers of services.
The analysis identifies different behaviours with the potential to cause incidents in the future. This approach has been particularly successful in identifying issues with anti-virus software. These are the common characteristics we have found on client’s servers that support different services:
- All have their CPU utilisation profiles change
- All change to the same profile (from vastly different profiles)
- Exhibit resource utilisation growth that can’t be explained by demand
Identifying these behaviours and reviewing change requests allowed the client to discover that these were driven by patching/upgrading of their anti-virus software. A solution that has been successful in avoiding up to 500 incidents a year.
Which way to shift?
Shifting left can provide the biggest gains but is also the most challenging to do and could be dependent on investment in skills, processes, tools, and environments. Shifting right may be seen as “giving up” but incidents can still be avoided – and without significant investment.
To effectively cover systems end-to-end, the advice is to embrace the DevOps methodology and shift both ways. It might seem daunting especially for large, high-performing systems, but with the help of tools, automation, and most importantly, the right engineering methodologies – teams can analyse the whole application and its services, no matter the complexity.
The best advice is, of course, to shift both ways but, most importantly “don’t stay still”.
At Capacitas, we help teams work faster and deliver cost-effectively with better quality using the DevOps methodology while leveraging machine learning and AI technologies. In a recent engagement, we worked with a large public service provider who had an urgent need to scale their systems to meet more than 6M daily transactions. Their teams were working in silos with no end-to-end visibility of their system with a lot of manual dependencies.
Using our DevOps methodology coupled with automation, we helped them:
- Scale systems to support 6M daily transactions (from 300,000)
- Reduced time needed for load testing from 3 weeks from start to finish to the single click of a button
- Empowered individuals and teams to take ownership of their non-functional testing using the testing framework and shifting left
- Cut environment costs by over £2M per annum while reducing testing overhead to deliver more value for money
If you would like to chat with us at Capacitas about how we can help your business shift and improve your overall performance, please get in touch with our team at contact@capacitas.co.uk or reach us via the website www.capacitas.co.uk
At Capacitas, we test and analyse across seven key areas of performance to achieve a much fuller and more complete understanding of your software. These are known as the 7 Pillars of Software performance:
- Throughput and response time
- Capacity
- Efficiency
- Scalability
- Stability
- Resilience
- Instrumentation
By evaluating your software in this manner, we’re able to look at all the available information, not just a fraction of it. With a more complete picture of your software, we’re able to create a much more detailed strategy to manage and enhance performance
Don't know how or which direction to shift?
Please reach out to us via our website (https://www.capacitas.co.uk/), or via email at contact@capacitas.co.uk.

