
Kubernetes hosting costs are spiralling unnecessarily!
In practice Kubernetes capacity is rarely limited by hardware. In fact, our observation tends to indicate that configuration of Kubernetes namespaces are more likely to lead to ineffective use of hardware capacity due to ‘bloat’. The net result is that cluster nodes cannot be driven up to high levels of utilisation and this causes the Kubernetes scheduler difficulties when trying to assign new pod workloads to nodes in the cluster. Additional costs are then incurred to increase cluster node capacity with more capacity that cannot be used effectively.
But, before I dive too deep into the detail, a primer on Kubernetes…
What is Kubernetes?
Kubernetes is a distributed system for orchestrating the scheduling of application programs across a cluster of hosting nodes. Kubernetes programs take the form of pods that have one or many containers associated with them. Application code runs in the containers.
Here are some compelling facts about Kubernetes:
|
69% |
The number of organisations adopting Kubernetes for managing container workloads |
|
71% |
The percentage of Kubernetes users who cite scalability as being an essential requirement when evaluating tool options |
|
$2.7B |
The expected overall market for containers in 2020. This is 3.5 times higher than 2017 |
It is clear the future of open source Kubernetes is bright as enterprise organisations continue to invest in containerisation technology. The top IT companies including Google, AWS, Oracle, Microsoft and many more are developing capability to support this platform. AWS are promoting their EKS Managed Service to simplify adoption:
Other dominant flavours of Kubernetes include:
AWS Elastic Container Service for Kubernetes:
Microsoft have announced the Azure Kubernetes Service (AKS) for managing the hosted Kubernetes environment:
.png?width=843&name=Azure%20Kubernetes%20Service%20(AKS).png)
How is Kubernetes Architected?
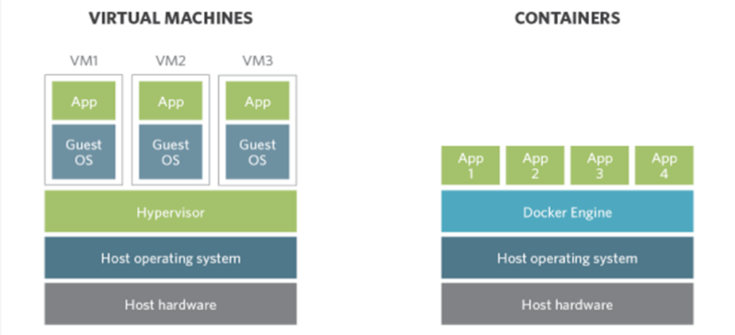
Part of the appeal of the Kubernetes architecture is the abstraction of containers which allows application code to run independently of operating system guest virtual machines. This allows containers to be freed from the constraints of traditional application deployment and facilitates the rapid and scalable deployment processes ideally suited for DevOps practices.
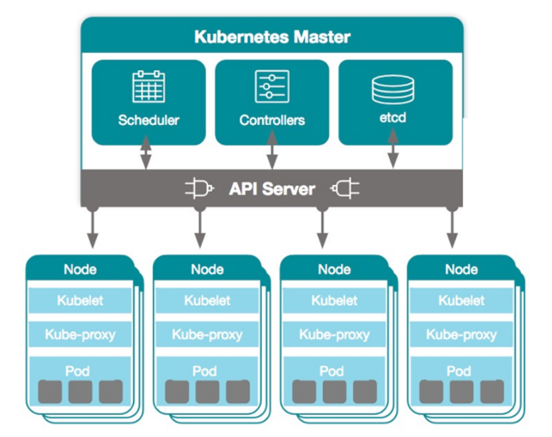
Architecturally the Kubernetes platform is structured to achieve a high degree of concurrent processing across many different application workloads that are co-hosted in the cluster of nodes. In the simple representation of the Kubernetes topology there are several components. The Master server provide scheduling and control functions for the container workloads whilst the Nodes provide processing capacity in the managed cluster. In the example the distinction between roles is clearly shown.
What are the rightsizing levers to control Kubernetes costs?
The capacity of a Kubernetes namespace can be restricted in one of four ways:
- SIZE OF PODS: by limiting the CPU and Memory allocated to pods and associated containers.
- FIXING THE NUMBER OF PODS: By allocating a pre-determined fixed number of pods.
- HORIZONTAL POD AUTOSCALING: By varying the number of pods based on the need for capacity. This is achieving by Horizontal pod autoscaling which uses measured metrics and compares against configured target values to determine how many pods should be active at a given point in time.
- HOSTING ENVIRONMENT: The capacity limits of the hosting environment.
It should be noted that CPU and Memory capacity can be limited at the namespace level by configuration of ‘Quota’ limits. In theory the aggregate capacity of all pods in the namespaces could exceed the capacity hardware. The use of pods and quota is intended to prevent this situation from arising and protect other workloads running in the cluster.
A major consideration for the cluster is the ratio of CPU Cores to Memory GB. The node hardware specification should provide a ratio that closely matches the CPU and Memory usage ratio overall. A poor match may suggest that the cluster is not optimised for workloads and result in more node capacity being required.
What are the common capacity planning mistakes in Kubernetes?
From a technical point of view a series of factors contribute to capacity ‘bloat’ of Kubernetes. These factors can resolve into very expensive hosting costs and therefore need to be considered when undertaking namespace sizing. At a high level the technical factors are:
- There is a tendency to massively over allocate pod CPU and Memory capacity as workload demand peaks that drive resource utilisation were not well understood. The Pod ‘Limit’ configuration was typically set extremely high. This means capacity is provisioned and unavailable to the Kubernetes Cluster and other users whilst the pods were active.
- Container and Pod CPU and Memory capacity was over allocated due to uncertainty over application start-up requirements.
- The ‘request’ configuration for pods and containers tends not used by many development teams. The purpose of this parameter is to ensure that capacity is used effectively from container and pod start up and the minimum necessary is allocated. The flexibility also allows the container and pod to increase or ‘balloon’ in capacity to the defined limit if additional processing resources are needed. Conversely capacity can be released to if unused and required by contending workloads.
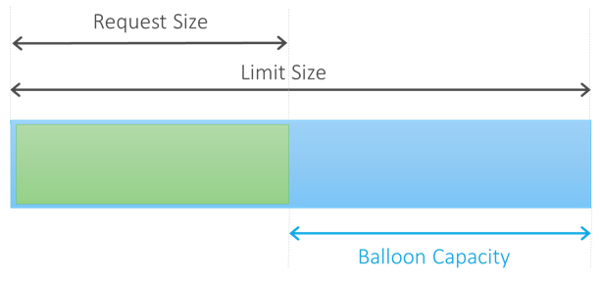
- If ‘request’ or ‘limit’ is not set in deployment configuration this may result in all the resources on the host being consumed. This is unfair to other Kubernetes workloads that may need to execute.
- ‘Limit’ is set way too high and too many pods are allocated. The combination of these factors significantly ‘bloats’ capacity use. In one case, a namespace was allocated with 16GB memory per pod and 150 pods in total. Individually each pod used 2 GB Memory, and in total 2.4 TB of Memory was wasted.
- The benefits of capacity elasticity are infrequently realised. Kubernetes provides an implementation of elasticity called ‘Horizontal Pod Autoscaler’; however, development teams are reluctant to invest effort to investigate opportunities this presents.
- A lack of reporting of AWS hosting costs at the Kubernetes. Development teams have no visibility of the Opex costs of their Kubernetes namespaces as this is abstracted from hosting costs. There is a general false perception that the Kubernetes costs are small.
- In meetings conducted with Development teams it became obvious that there was a lack of knowledge about and how to configure Kubernetes deployment files (.YAML files) to take advantage of capacity features.
How can Kubernetes/AWS Cost Savings be achieved rapidly?
How to drive down your Kubernetes costs.
We operate a 6-phase cost optimisation process to ensure the benefits of Cloud Cost management are realised. The process is agnostic of technology and has been successfully utilised in the context of AWS Cost control of Kubernetes container applications.
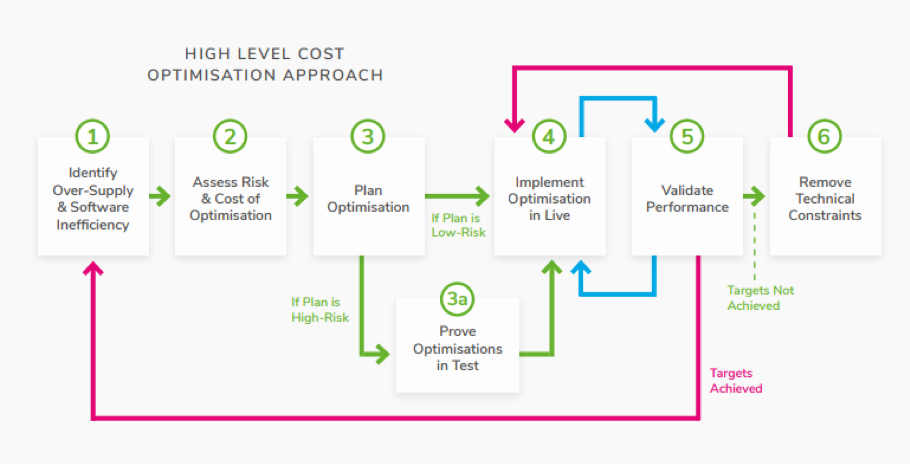
The process resolves 4 key problem areas that contribute to over provisioning and high Opex costs:
- Oversizing
- Software inefficiency
- Application inelasticity
- Sub-optimal architecture
For a more detailed description of the process download our Guide to Cloud Cost Optimisation in AWS.
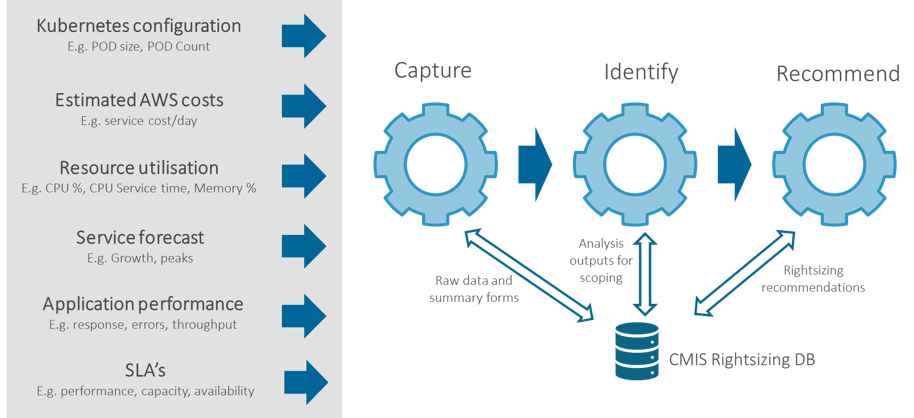
In delivering the process 6 data inputs are exploited. In each case the data is captured and analysed using proprietary methodology to identify and prioritise suitable optimisation opportunities. Appropriate recommendations for optimisation are then taken to the development teams and a plan of action is agreed and implemented. Later the optimisation benefits are measured and reviewed.
Underpinning these data and analysis requirements is a central Capacity Management Information System which captures all data entities used and generated in the process.
What are the Benefits of Kubernetes Optimisation?
In a large cost saving exercise conducted in 2018, Capacitas achieved an 8:1 ROI by exercising the rightsizing process with the Development teams and DevOps teams performing deployment. The client in question had invested heavily AWS hosting and had built a large cost Kubernetes Clusters.
Working with the client’s development teams we achieved several core Kubernetes savings:
|
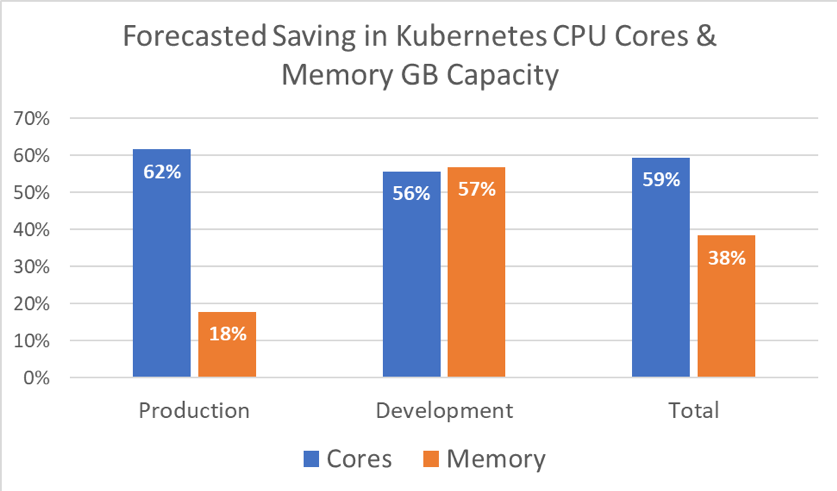
59% |
Kubernetes production and development cluster CPU core capacity identified for reduction. |
|
38% |
Kubernetes production and development Memory GB RAM capacity identified for reduction. |
|
2.7k |
Total number of oversized CPU Cores identified |
|
3.7K |
Total amount of oversized Memory GB identified |
|
67 |
Number of AWS EC2 instances to be saved when the sizing recommendations are applied. |
Relative cost savings broken down by environment:
Conclusion
Kubernetes optimisation is not a straight forward process. And in our experience, many Development teams are not yet equipped to deal with the challenge. The result is a capacity provisioning issue at the cluster layer and has causing excessive consumption of hosting capacity.
To help organisations like yours control ‘bloat’ associated with Kubernetes, we’ve devised a methodical approach and process to right-sizing. These methods and processes have achieved an 8:1 ROI for some of our customers.
To learn more about our Cloud Cost optimisation service, follow this link.


