Performance Testing Process
The first thing to get right when implementing DevOps performance is to ensure that the right process is in place. Often teams start by looking at tooling (perhaps because that’s more exciting!) but, without the right process, tools will be chosen wrongly and poorly implemented.
A good DevOps process consists of 6 activities:
-2.png?width=800&name=Blog%20Images%20(1)-2.png)
A combination of these activities will be carried out for any change delivered by the DevOps team.
 Risk Assessment
Risk Assessment
Objective
A good process starts with understanding the performance risk of any change. Taking ownership of this risk as a DevOps team. Planning steps to mitigate it.
Approach
Performance risk assessment takes place at the same time as maturing, planning, estimating. As soon as the team starts thinking about the items in the backlog, they start thinking about risks to performance.
Having this performance mindset is critical to making sure that the end product performs – while all the team should have the same performance focus, it can help to appoint a Performance Champion to lead on it; more on that later. Performance NFRs need to be reviewed and updated where needed – for help on setting NFRs see our NFR Template.
It’s helpful to classify the risks, as well as the requirements, across the 7 key pillars of software performance.
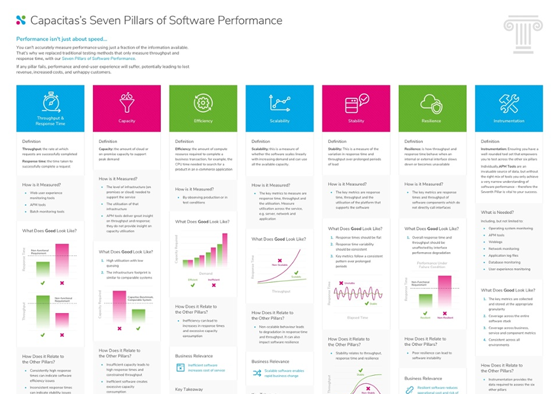
 Performance Design and Build
Performance Design and Build
Objective
Use team mindset to eliminate risks early. On one hand using knowledge of performance behaviours and antipatterns to improve implementation. On the other using understanding of change and implementation to improve smart test design, scripting and data.
Approach
There’s no need to wait for code to be checked in to start improving performance.
The first step in a performance design is to review the implementation for performance anti-patterns – behaviours which will impact performance. At the same time the team will start updating scripts, data, mocks etc. to prepare for performance testing.
These alterations need to be ready before changes are checked in so that tests are ready to run automatically without delaying delivery.
At the end of this phase of the process everything is ready for the DevOps engineer to check in their code and deploy it… well, almost.
 Performance Unit Testing
Performance Unit Testing
Objective
Reduce risk of build failures during continuous integration.
Approach
An important stage in the process which often gets overlooked is assessing performance at a unit or profiling level, before the code is actually checked in and deployed.
This is down to the individual developer, using profiling tools (often available in developer’s IDEs, or sometimes specialised tools may be required) or timed unit tests, to provide rough measures of time and resource taken by different high-risk code areas.
When this is complete, the developer will be as confident as possible on the performance of the code and is ready to start automated performance testing.
 Performance Component Test
Performance Component Test
Objective
Test for a subset of key pillars of performance in a component environment.
Approach
There are two levels at which tests may be run at this stage in the process: Service component test – in a CI environment for performance, focussing on the performance of an individual service.
Service component test – in a CI environment for performance, focussing on the performance of an individual service.
Product performance component test – in a Team Performance Test Environment, focussing on performance of the entire product delivered by the team.
For either type of test, mocking of any interfaces out of scope is crucial to ensure the correct focus.
Everything from setup of the environment, through to analysis of the platform, will need to be fully automated using appropriate scripts and tooling to achieve full continuous delivery.
At the end of this step, the team will have a full view of the performance of the product or components for which they are responsible.
 Performance Integration Test
Performance Integration Test
Objective
Test for all key pillars of performance in an integration performance test environment, when and where an integration performance risk is present.
Approach
An integration performance risk means that there is some kind of interaction between the products developed by multiple DevOps (or other) teams. A single team (often separate from the individual product teams) will be responsible for this risk.
This team will carry out the same steps as in the Performance Component Testing, but in a fully integrated environment without any mocking present (except potentially 3rd party systems).
This is particularly important in large organisations with dozens of product teams producing component parts of the final system but needs to be considered with any number of teams.
Once this is completed, the system changes are ready for release to production. But the process isn’t finished yet…
 Production Performance Assessment
Production Performance Assessment
Objective
To take ownership of performance where it really matters! To improve the Performance Engineering process by completing the feedback loop. To respond quickly and proactively to any production performance incidents. To mitigate the risk of environmental, operational or usage differences between test and production, and to manage any other residual performance risk.
Approach
There are three types of production performance assessment which should be implemented where appropriate, depending on the Performance Risk Assessment:Performance health check – using dashboards, alerting etc. to compare current performance to past baselines and NFRs.
Production performance model validation – validating the model used for constructing performance tests.
Production performance testing – repeating performance testing in production.
Production performance assessment is never completed, but is an ongoing activity, continuing to track and own any risks while delivering the performance the business asked for, as new changes continue to make their way through the process, are deployed, and utilised.












